A Versatile Framework for Analyzing Galaxy Image Data by Implanting Human-in-the-loop on a Large Vision Model
The exponential growth of sky survey datasets provides a growing precious deposits for astronomers while challenging their ability to dig meanful scientific information in them. Unsupervised machine learning has been proved to be efficient to learn potential pattens hidding behind massive unlabeled astronomic data, as works like Hayat et al., 2021and Xu et al., 2023 showed. However, the newest results come from studies of large language and multimodal models remind us that there are many more things we can do to make a state-of-the-art foundational model for the research of galaxies.
As an attempt, we developed a framework of pre-training and finetuning an astromical large vision model (LVM) and applying it to multiple downstream tasks which include a human-in-the-loop (HITL) application (online version in preparation) that allows astronomers to analysis galaxy image data in a custom way. Full details of this work can be found in Fu et al., 2024.
Taking benefits from recent research (Fan et al., 2022) in computer science, we construct our LVM based on an encoder-decoder structure where Swin-Transformer serves as fundamental blocks. This structure enables us to capture and synthesize information at various levels of images at smaller computing and memory cost compared to traditional Transformers or ViTs. In this work, it takes approximately 196 hours using 8 NVIDIA A100s with 80GB of graphic memory to complete the pre-training stage of our model with 100M parameters in total on 76M galaxy stamps come from DESI Legacy Imaging Survey (Stein et al., 2021).
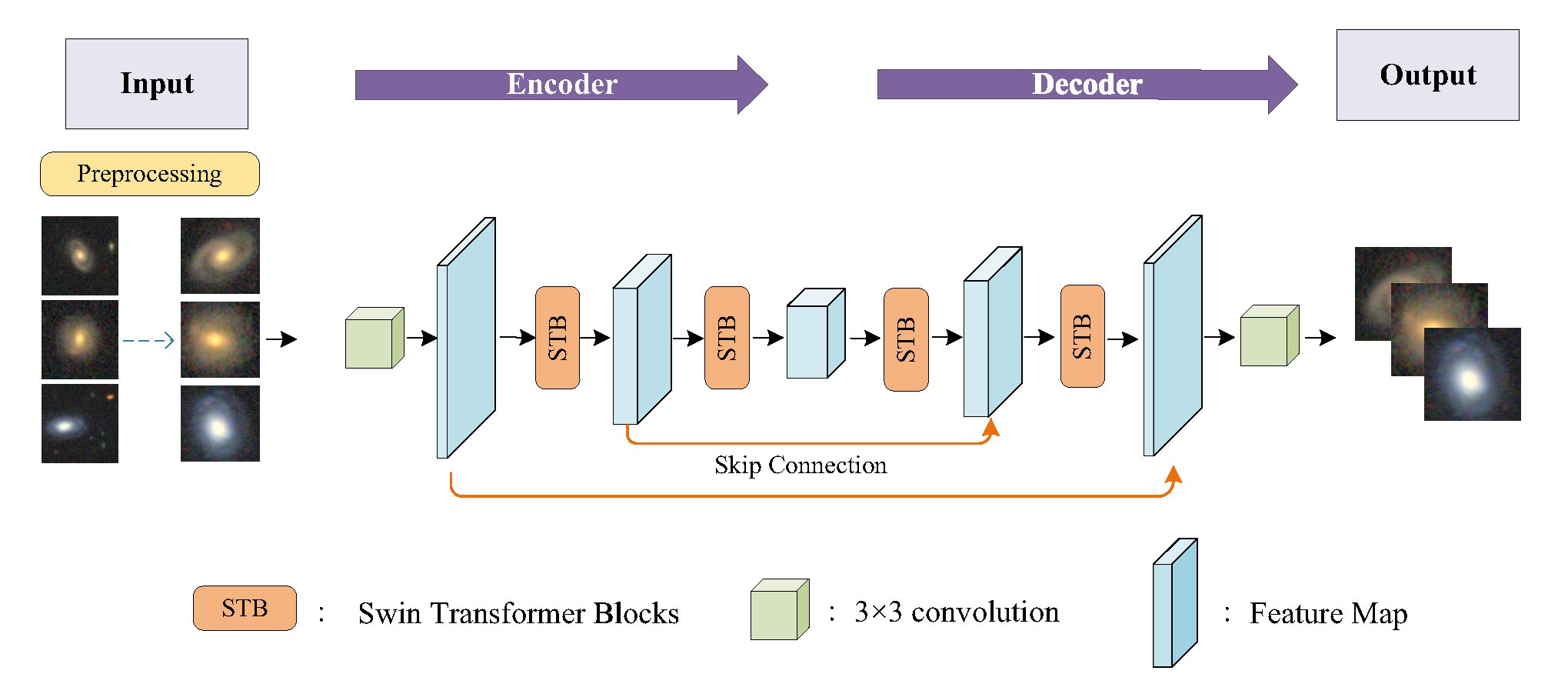
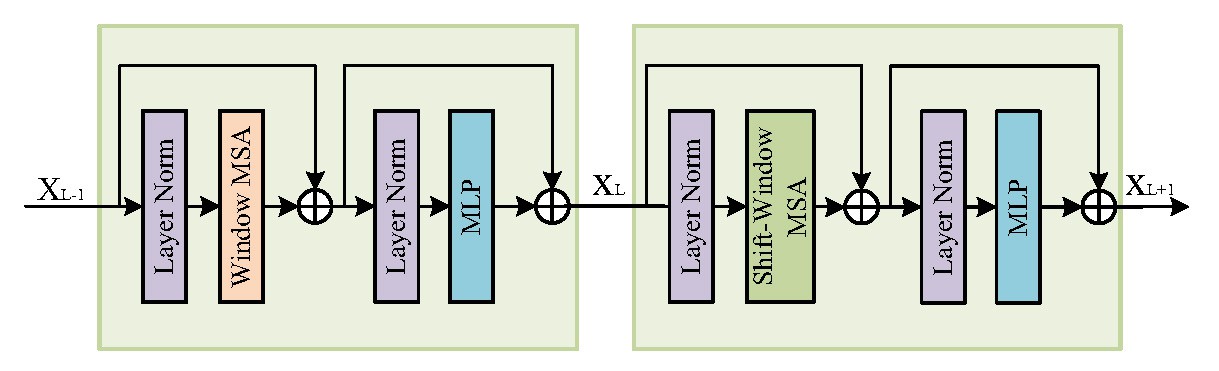
Figure: Upper: the structure and pre-training process of our LVM. Lower: the detailed structure of Swin-Transformer layer in LVM.
After pre-training, we conducted a multiple downstream tasks training for our LVM by attaching different task-specific neural networks to its encoder. The tasks we chose include galaxy classification, image restoration and image reconstruction. We adopted an active strategy where tasks that demonstrate lower performance metrics receive a larger proportion of training dynamically and proved that it outperforms the strategy where all tasks are equally trained.
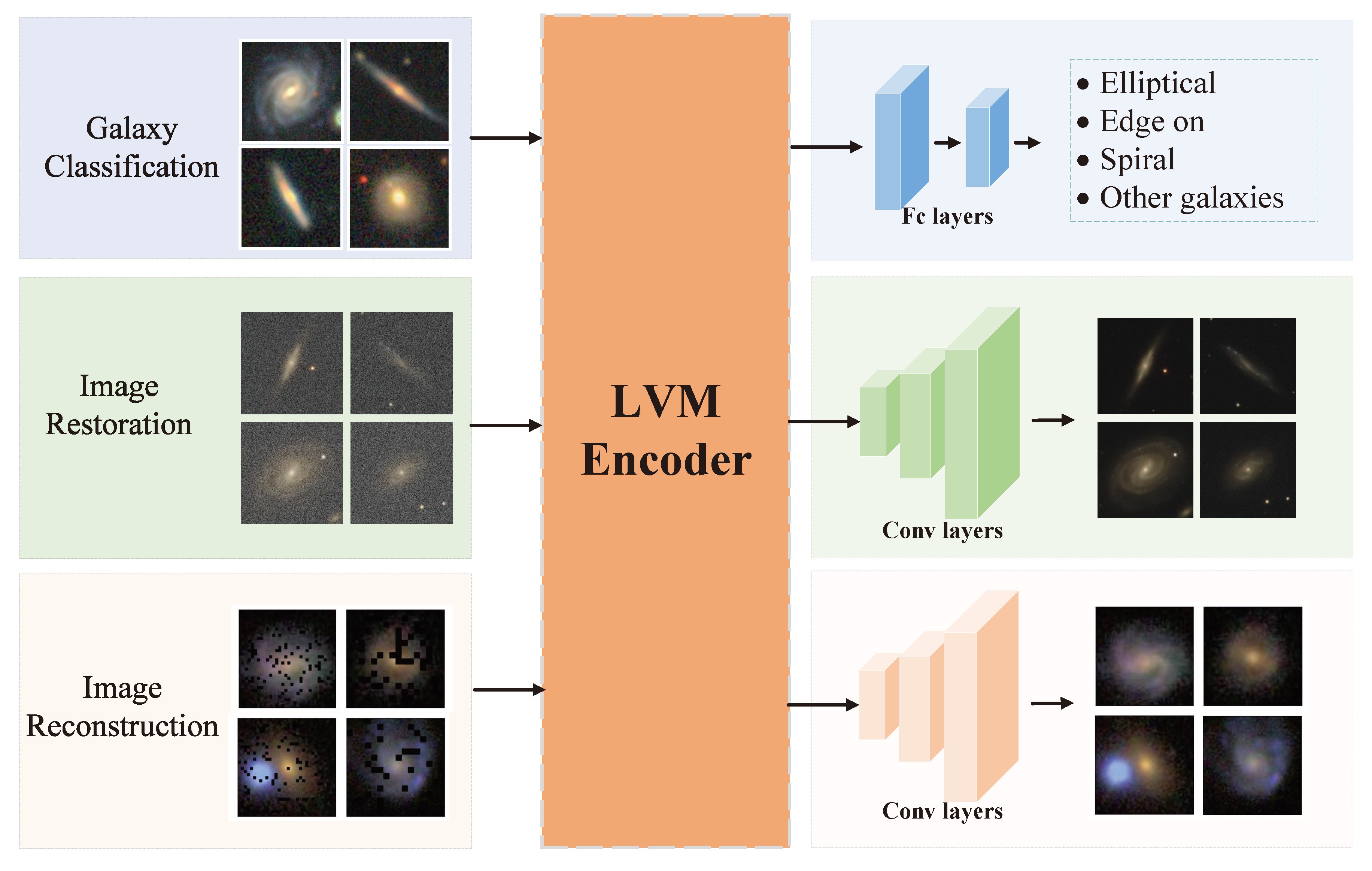
Figure: The downstream tasks we used to finetune our LVM.
After multi-task finetuning, we deployed our LVM to 2 specific task to show its capabilities: galaxy morphology classification and strong lens finding. For the first task, we used the labels come from GalaxyZoo DECaLS (Walmsley et al., 2022) to classify galaxies into 5 types and compared the performance of our model in few-shots learning with some other classic models. For the second task, we employed our LVM as backbone of Mask R-CNN and compared its performance to ResNet + Mask R-CNN. The results show that our model outperforms traditional methods.
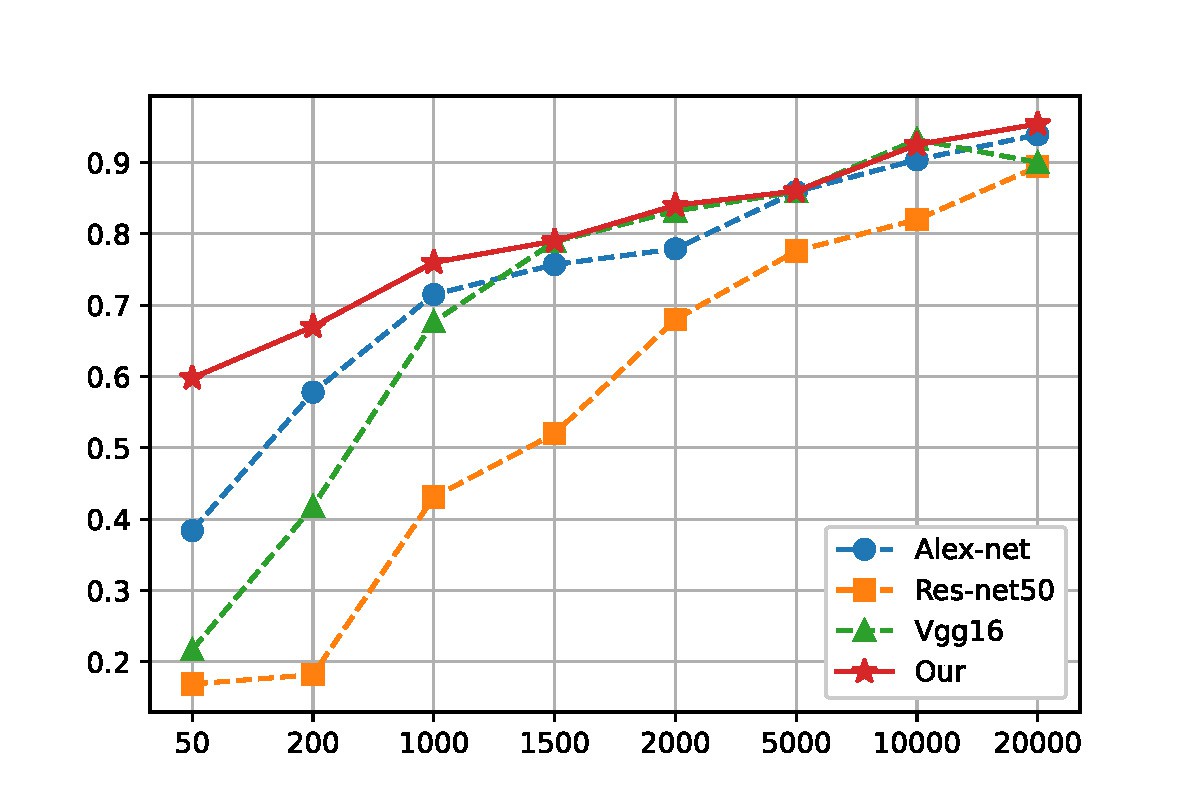
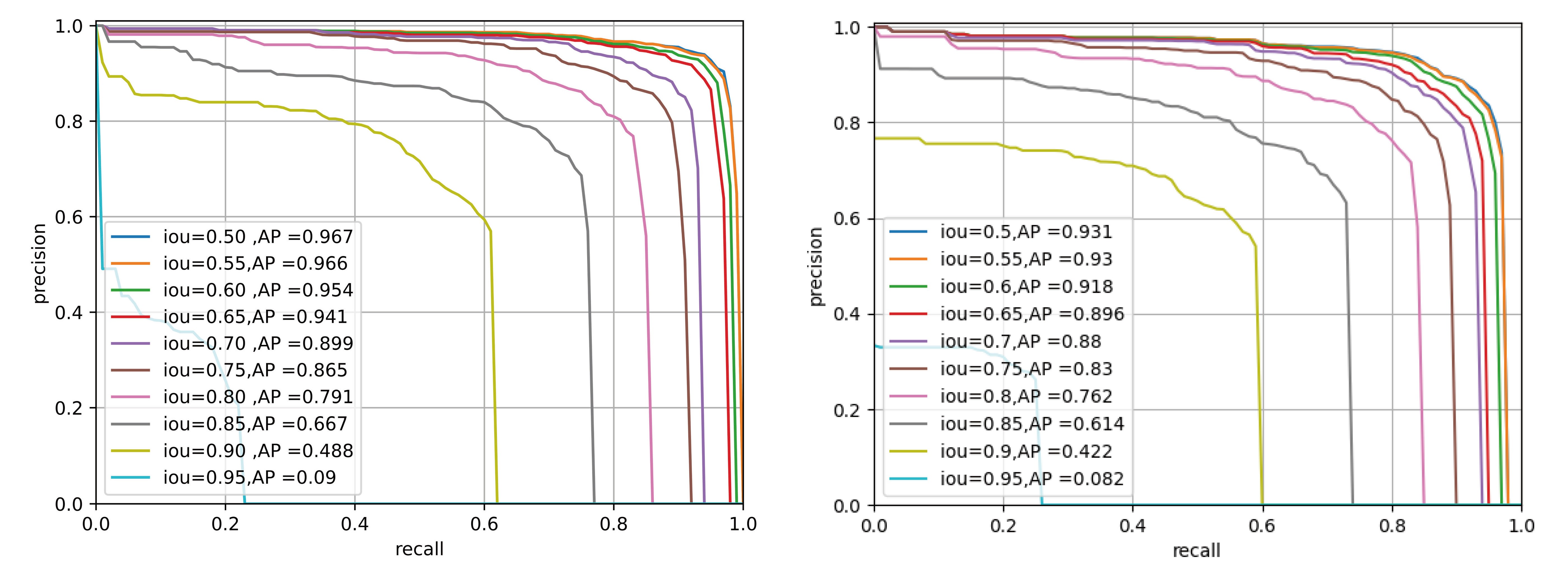
Figure: Upper: comparison of our model with other models in few-shot morphology classification task. Lower: comparison of our model (left) with ResNet (right) in strong lens finding task.
Furthermore, we developed a HITL application base on the feature vectors of galaxy stamps extracted by our LVM. It learns users' custom preferences from positive and negative images they given and makes better prediction of them after loops of posting new unlabeled image to users, collecting their feedback and adjusting on them. During testing, our application succeeded in finding high quality candidates of various type of galaxies after fewer than 10 iterations, even with only 3 examples of targeted galaxy type given in the beginning.
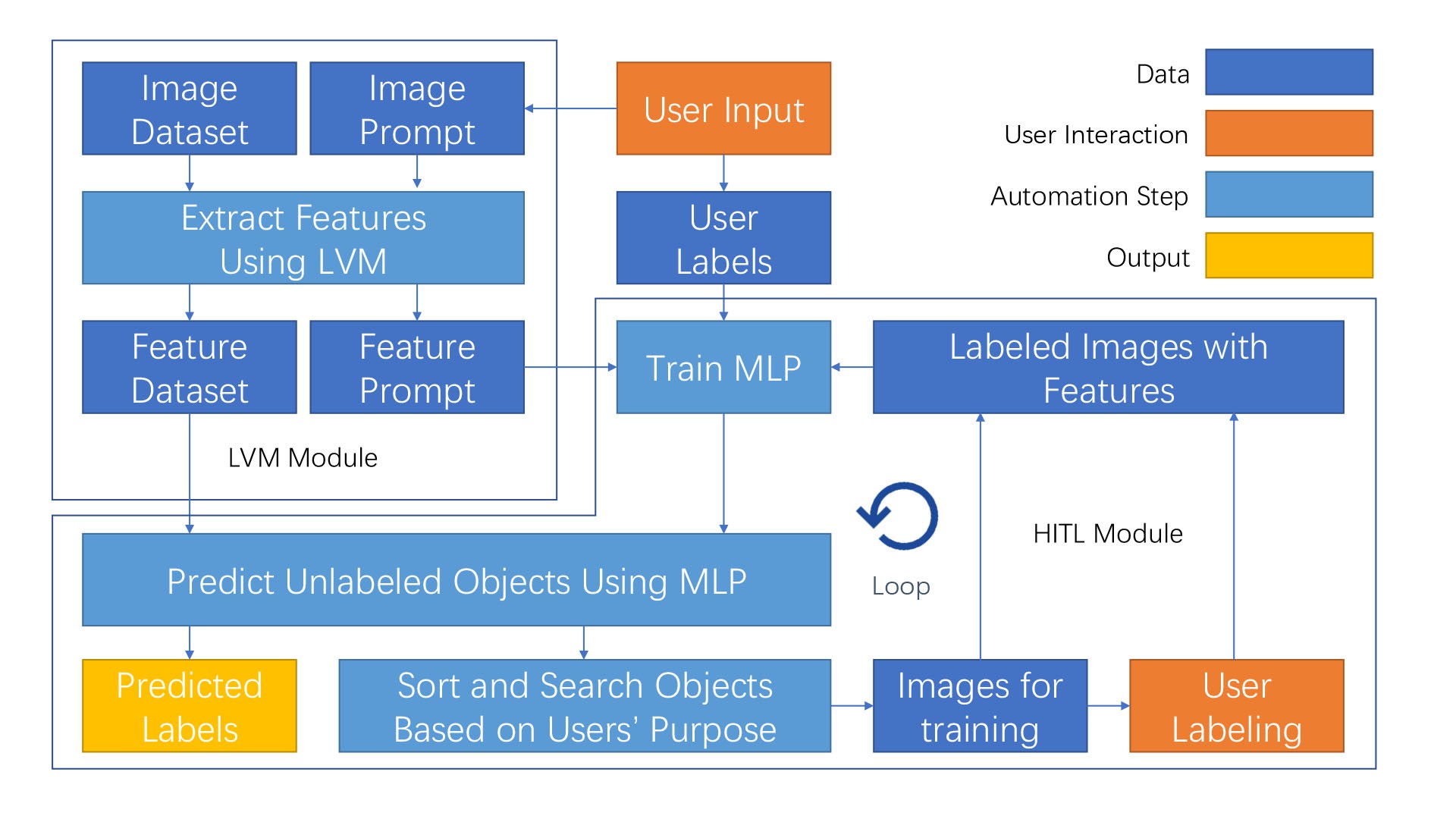
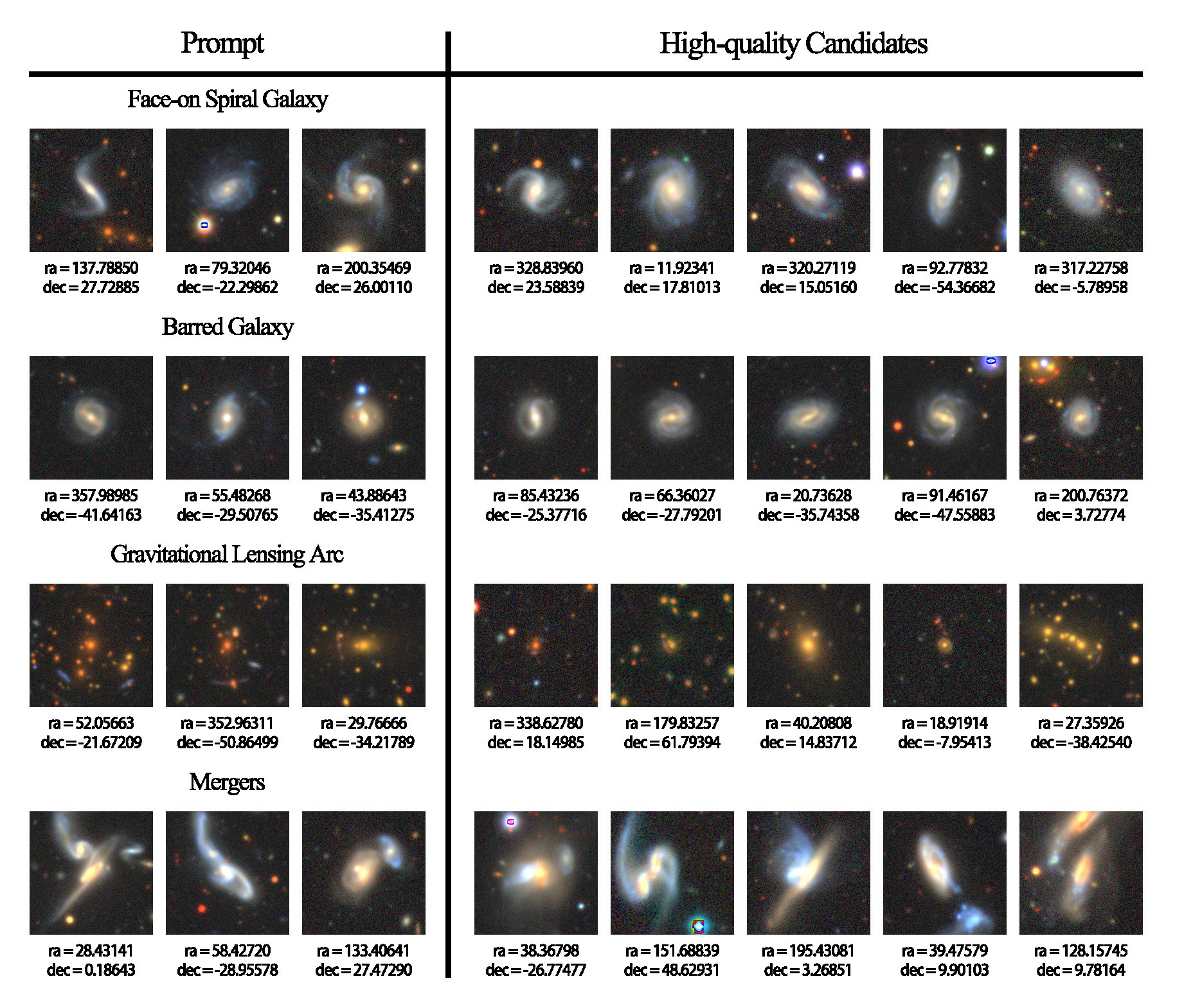
Figure: Upper: the design of our HITL application. Lower: galaxy images of different types serving as initial prompt and high quality candidates found with them.