Leveraging A.I. for galaxy formation and Evolution
The on-going or upcoming next generation telescopes like JWST, Euclid and CSST are expected to greatly expand the boundary of our cognition about galaxies and their evolution with an unprecedented sky survey sample in depth and width. However, the vast and intricate nature of astronomical datasets poses a significant challenge to astronomers who want to extract meaningful scientific information.

Figure: Compared to HST, JWST reveals unprecedented details of distant galaxies to us, which also requires advanced data analysis techniques to fully utilize their scientific value.
credit: ARC Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D) (https://www.eurekalert.org/multimedia/1004630)
Fortunately, as emerging data processing technologies, deep learning methods have been proved to be efficient on dealing with such problems caused by the amount and complexity of data in most areas of astronomy in recent years. Supervised learning methods, which idea is to teach the algorithm to solve the problems as massive known examples given, is most widely used due to its reliability. For the research of galaxy, these methods have been used to detect (Lao et al., 2021), classify (Banerji et al., 2010,Wu et al., 2019) and analysis (Zhou et al., 2023) them. However, these methods face lots of problems when known data is few or they are needed to transfer between different data domains (e.g. galaxies in the early and late universe) since they require enough specific data to solve a specific problem.
To make up this shortcoming, unsupervised learning methods, which can learn potential patterns from massive unlabeled examples, have been paid more and more attention recently. Some successful attempts include Hayat et al., 2021and Xu et al., 2023. Despite the idea of acquiring unbiased knowledge directly from data is promising, there is still a gap between the performace between unsupervised and supervised methods when we only talk about the final results in astronomy.

Figure: An UMAP figure of galaxies based on their feature vectors extracted by one of our unsupervised model, showing that unsupervised methods is capable to understand the differences and relations between galaxies in morphology.
But as we turn our gaze to the area of natural language processing, unsupervised methods have achieved tremendous success in the autoregression pre-training of large language models. After supervised finetuning and human alignment, these models (like GPT-4 and Claude 3.5) are able to outperform models specially designed for a single task in most tasks with their much larger model and pre-training data size.
Inspired by this fact, we have trained an unsupervised large vision model with 100M parameters on 76M galaxy stamps from DESI Legacy Imaging Surveys and finetuned it on multiple tasks to stimulate its ability to to solve practical astronomy problems. Further more, we designed a human-in-the-loop module to allow the model to learn the preference of specific users from their multiple rounds of feedback to solve their specific problems in the galaxy morphology classification. We introduced these experiments and their potential in Fu et al., 2024, and we will improve the performance, versatility and usability of our model to apply it on the research or JWST-SPRING in the future.
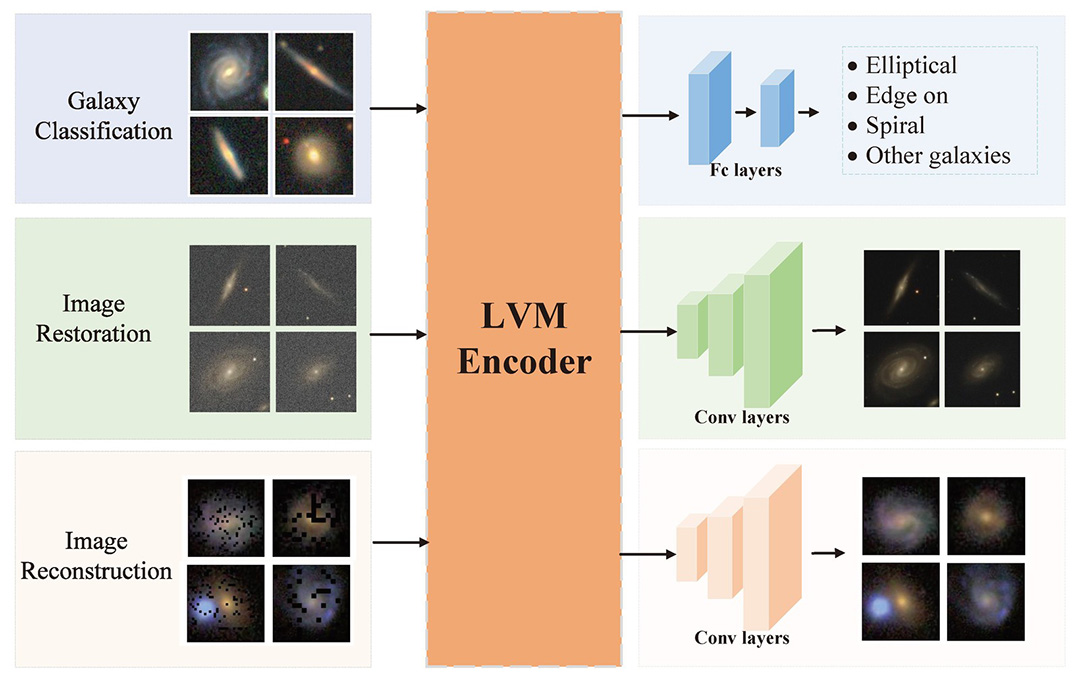
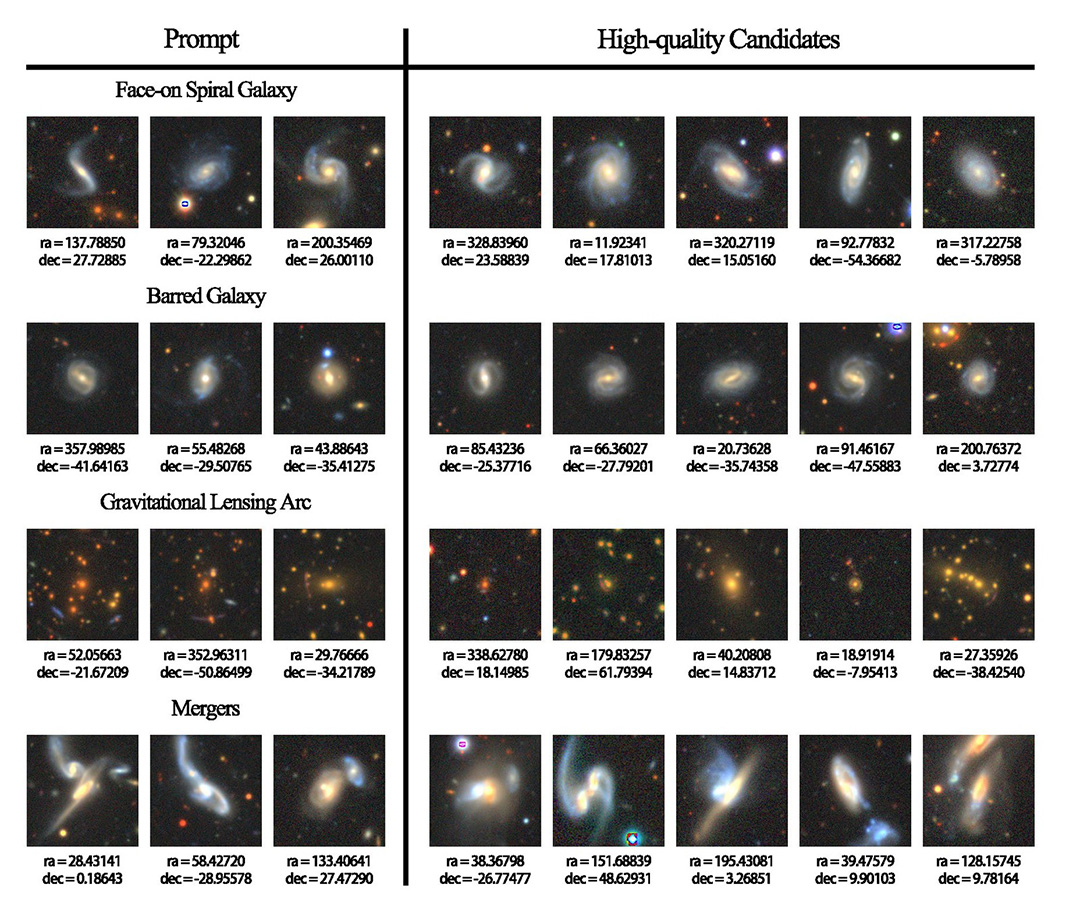
Figure: Top: the multiple tasks used to finetune our unsupervised model, which includes galaxy classification, image restoration and image reconstruction. Bottom: some results come from our human-in-the-loop module. Among each we start with only 3 positive and 3 negative examples ( i.e. stamps contain galaxies of types that we are interested in or not) and succeed in get a list of high-quality candidates after few than 10 iterations.